








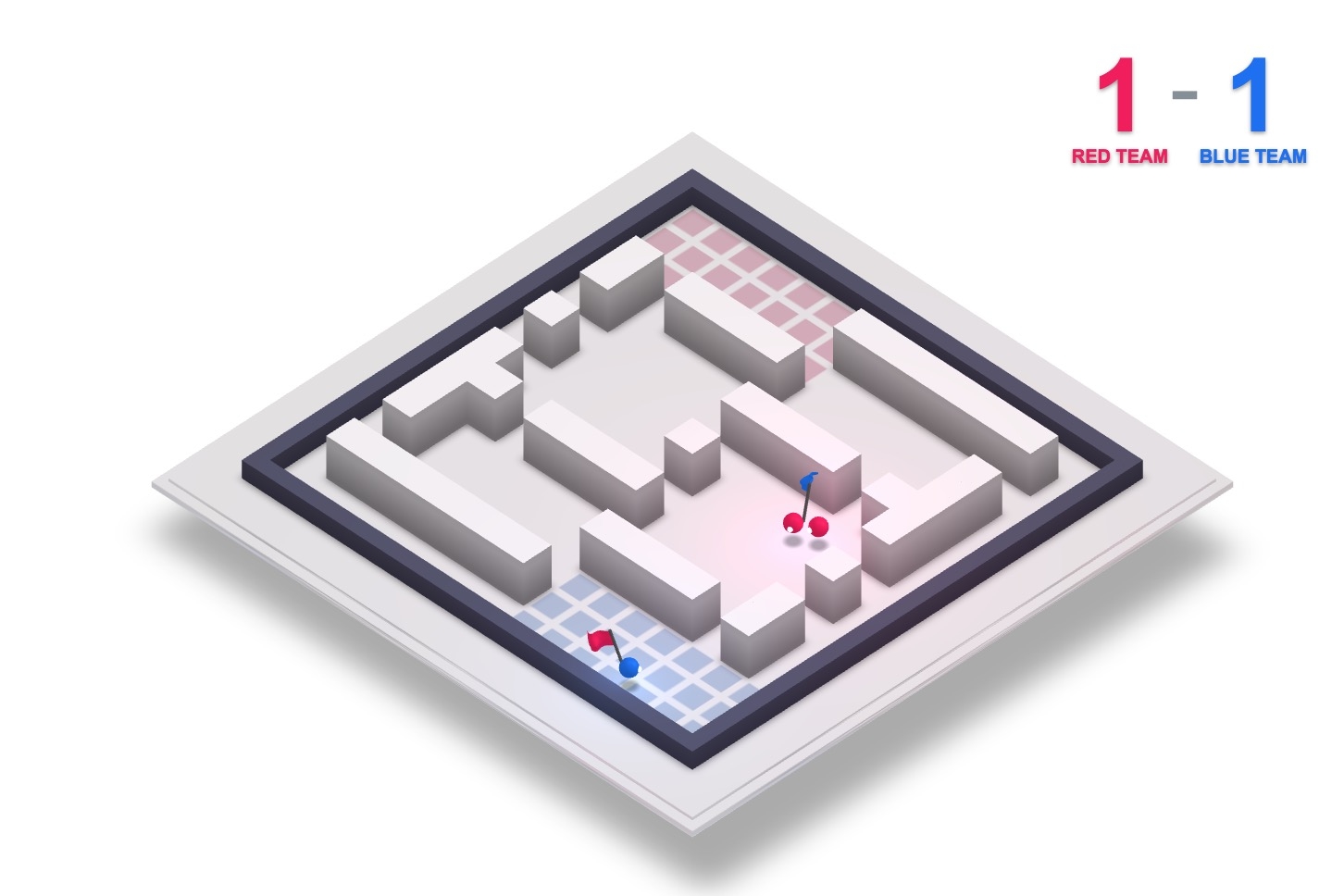
Nhóm phát triển đã để cho DeepMind tập chơi ở chế độ cướp cờ, trong đó bản đồ thay đổi từ trận này sang trận khác. Trí tuệ nhân tạo phải tự học các chiến thuật khác nhau để thích ứng với từng bản đồ mới, một việc làm rất dễ với con người. Ngoài ra, DeepMind còn phải kết hợp với các đồng đội của mình để chống lại đối thủ, và sau đó thay đổi cách chơi dựa trên phong cách của đối phương.
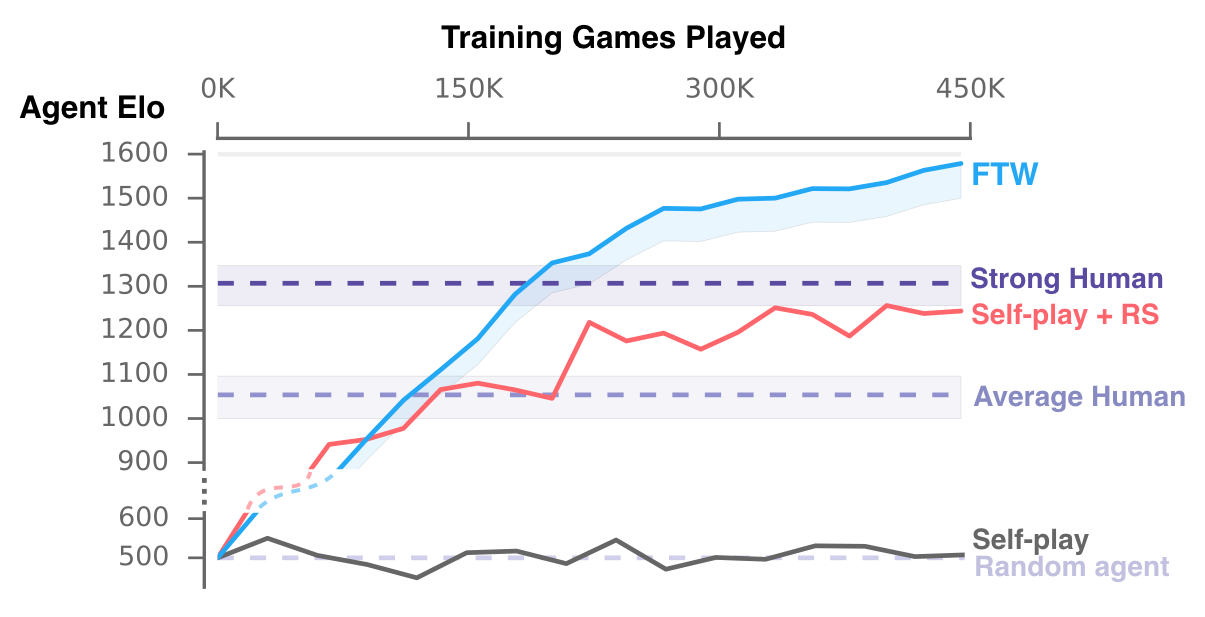
Toàn bộ quá trình học hỏi đều bắt đầu từ con số 0, từ cách quan sát, hành động, tác chiến và chiến đấu ở những môi trường không có tầm nhìn rõ ràng, và chỉ nhận được 1 tín hiệu hỗ trợ trong mỗi trận đấu: team của DeepMind có thắng hay không. Các nhà nghiên cứu đã huấn luyện nhiều hệ thống trí tuệ nhân tạo khác nhau để chơi game này, giống như tập luyện cho con người. Mỗi hệ thống được đưa các tín hiệu thông báo khác nhau, giúp chúng học để đạt được mục tiêu. Sau đó các hệ thống này đối đầu lẫn nhau và với các người chơi thuần túy trong những trận đấu nhanh và chậm để cải thiện bộ nhớ cũng như có độ ổn định trong các cách phản ứng tình huống. Các báo cáo cho thấy tỉ lệ chiến thắng của trí tuệ nhân tạo cao hơn so với con người (không có gì đáng ngạc nhiên), nhưng chúng cũng hợp tác với nhau tốt hơn con người. Các hệ thống cũng học được các cách hành xử của con người như di chuyển theo đồng đội và núp trong căn cứ đối phương.
Nếu không có gì thay đổi, những trí tuệ nhân tạo như thế này sẽ được mở rộng việc học hỏi ra ở nhiều tựa game phức tạp hơn như StarCraft II và Dota 2. Đây là những tựa game đòi hỏi các hệ thống phải chơi như một con người thực thụ. Không quá khó để thấy rằng trong tương lai, các đội tuyển thể thao điện tử có thể sẽ sử dụng công nghệ này để cải thiện chất lượng cũng như kỹ năng của mình.
Bình luận (0)