








Việt Nam là nước xuất khẩu cà phê lớn thứ hai thế giới và đóng góp hơn một nửa nguồn cung Robusta toàn cầu. Sản lượng cà phê niên vụ 2022/23 đạt 29,75 triệu bao, trong đó Robusta chiếm hơn 95%.
Trong Đánh giá thường niên 2021/2022 của Tổ chức Cà phê quốc tế, Việt Nam đứng đầu về năng suất canh tác cà phê với 2,4 tấn/ha. Sản lượng cà phê ở Việt Nam được tạo thành từ hạt Robusta, Arabica, Cherri, Moka và Culi, là những hạt cà phê phổ biến nhất được trồng ở Việt Nam.
Tuy nhiên, giá cả các mặt hàng nông sản nói chung và giá hạt cà phê nói riêng thường không ổn định và có thể biến động mạnh vào thời điểm bội thu, khiến thu nhập của nông dân bị tác động đáng kể và gây thiệt hại cho nền kinh tế.

Từ trái sang phải: Sinh viên Khoa Khoa học, Kỹ thuật và Công nghệ RMIT: Lâm Tín Diệu, Nguyễn Hải Minh Trang, Nguyễn Phương Nam (hàng trên), Lê Ngọc Nguyên Thuần, Đoàn Chánh Thống (hàng dưới)
Nhằm nghiên cứu giải pháp cho vấn đề này, trong khoảng thời gian bốn tháng, một nhóm sinh viên năm cuối ngành Cử nhân Công nghệ Thông tin, Khoa Khoa học, Kỹ thuật và Công nghệ, gồm Nguyễn Hải Minh Trang, Đoàn Chánh Thống, Lê Ngọc Nguyên Thuần, Nguyễn Phương Nam và Lâm Tín Diệu, đã huấn luyện và đánh giá sáu mô hình máy học (ML) để dự đoán giá cà phê, có thể hỗ trợ nông dân Việt Nam đưa ra quyết định sáng suốt về mùa vụ và lập kế hoạch phù hợp, tối ưu lợi nhuận và giảm thiểu tổn thất.
"Chúng tôi đã phát triển sáu mô hình ML, cụ thể là LSTM, GRU, ARIMA, SARIMA, SVM và RF, dựa trên lịch sử giá cà phê, giá xăng dầu, nhiệt độ và lượng mưa, để dự đoán giá cà phê Robusta ở tỉnh Lâm Đồng và nhận thấy mô hình RF, sử dụng toàn bộ bộ dữ liệu, là hiệu quả nhất", Trang nói.
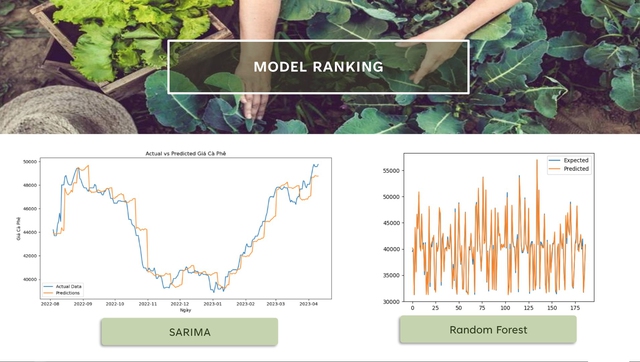
Trong số 6 mô hình học máy, mô hình RF, dùng toàn bộ bộ dữ liệu, cho ra kết quả tốt nhất
"RF có thể kết hợp bộ dữ liệu phong phú hơn và xử lý được mối quan hệ phi tuyến. Ngoài ra, giá nhiên liệu cho thấy là một yếu tố dự báo quan trọng và vượt trội so với tất cả các tính năng được thử nghiệm khác kết hợp lại".
Nhóm nhấn mạnh rằng mô hình này có tiềm năng tiếp tục cải tiến bằng cách nghiên cứu và bổ sung thêm tác động của năng suất cây trồng, xu hướng thị trường và các sự kiện địa chính trị đến giá cả của nông sản.
Mỗi thành viên trong nhóm phải đối mặt với những thách thức khác nhau trong quá trình thực hiện dự án, chẳng hạn như thiếu hiểu biết chuyên sâu về các mô hình ML khác nhau, truyền đạt hiệu quả độ phức tạp của những gì các bạn thực hiện sang trang miền AI, hoặc quản lý thời gian và sự trao đổi khi làm việc từ xa. Tuy nhiên, bằng cách đầu tư thời gian đáng kể vào nghiên cứu, đào sâu vào các bài báo nghiên cứu liên quan đến AI và ML, đồng thời nâng cao kỹ năng kỹ thuật và cộng tác, các bạn đã cải thiện kỹ năng nghiên cứu AI cho các vấn đề trong thế giới thực và có khả năng phát triển nghiên cứu của nhóm thành sản phẩm thực tế.
"Thách thức chủ yếu đối với chúng tôi xoay quanh việc thu thập và tích hợp dữ liệu", Thuần chia sẻ.
"Mặc dù việc phát triển mô hình khá đơn giản, thời gian đáng kể cần phải đầu tư vào việc thu thập và kết hợp dữ liệu đã đặt ra trở ngại rất lớn cho chúng tôi. Mỗi thành viên trong nhóm đã trải qua các cung bậc học hỏi và tiến bộ vượt bậc cả về kỹ năng chuyên ngành và điều phối dự án, từ nghiên cứu chuyên sâu, đến đẩy mạnh đổi mới và đưa ra các giải pháp mới".
Vào thời điểm thực hiện nghiên cứu, Nam làm việc từ Hà Nội và đã đi làm toàn thời gian. Để phòng ngừa việc chậm tiến độ và những gián đoạn tiềm ẩn, Nam cho biết cả nhóm đã thiết lập các cuộc họp hằng tuần và duy trì liên lạc thường xuyên, vừa để động viên nhau đi đúng hướng, vừa hoàn thành tốt khối lượng công việc được giao.
Dự án capstone của nhóm được sự hướng dẫn chặt chẽ của các giảng viên Khoa Khoa học, Kỹ thuật và Công nghệ, RMIT Việt Nam. Kết quả dự án gần đây được trình bày tại một sự kiện quốc tế uy tín - Hội nghị quốc tế IEEE / ACIS lần thứ 8 về Dữ liệu lớn, Điện toán đám mây và Kỹ thuật khoa học dữ liệu (BCD 2023) – cùng với các nhà nghiên cứu, khoa học, kỹ sư, chuyên gia trong các ngành Dữ liệu lớn, Điện toán đám mây và Khoa học dữ liệu.
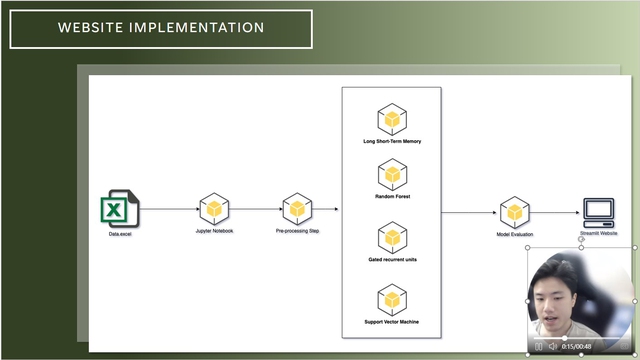
Sinh viên Nguyễn Phương Nam trình bày cách trang web mô phỏng giá cà phê hoạt động
Nhóm nghiên cứu có kế hoạch tinh chỉnh các mô hình dựa trên phản hồi các bạn nhận được từ phần thuyết trình trong hội nghị, đồng thời cũng tìm hiểu thêm các hướng tiếp cận khác để cải thiện độ chính xác và khả năng áp dụng các dự đoán của họ.
"Chúng tôi dự định đi sâu hơn vào các kỹ thuật tiên tiến và các phương pháp mới nổi trong lĩnh vực này để củng cố hơn nữa kết quả nghiên cứu mà nhóm đã thực hiện được", Thống cho biết.
"Bên cạnh đó, chúng tôi dự kiến sẽ hợp tác với các chuyên gia khác trong lĩnh vực và khai thác các quan hệ đối tác tiềm năng để mở rộng phạm vi và tác động kết quả nghiên cứu của nhóm".
Nhóm dự kiến sẽ tiếp tục lặp lại và nâng cấp nghiên cứu để có thể đóng góp thiết thực vào lĩnh vực Dữ liệu lớn và AI đang phát triển không ngừng từ nghiên cứu cụ thể của các bạn.
Bình luận (0)